Chatbots and AI copilots that can write fluent emails and computer code exploit statistical probabilities in natural or artificial language to predict the next token in any given sequence. But “the moment you try to breach that boundary of language, you start to run into problems, and that’s what people are running into now,” says Rohan Kodialam, a former data scientist at Citadel. “If you try to use [generative AI] on a real business application where it’s not just about saying stuff but about doing stuff, all of a sudden you are now in a much more difficult spot.”
The problem helps explain growing skepticism about the global AI boom. Last month an MIT project on “the agentic web” reported that despite up to $40 billion in enterprise investment, 95% of organizations are seeing no return. The study’s evidence was thin, but U.S. Census Bureau data does show fewer large companies adopting AI in their operations—the first sustained decline since ChatGPT’s 2022 debut.
To address that gap, Kodialam and engineer Jamie Bloxham cofounded Sphinx, a startup building AI designed to work reliably with data. The seven-person firm, based in Queens, New York, last week raised a $9.5 million seed round led by Lightspeed, with backing from Bessemer Venture Partners, BoxGroup, K5, Impatient Ventures, Steve Cohen, Naveen Rao, and others. Kodialam is Sphinx’s CEO; Bloxham is CTO.
Designed for data scientists, Sphinx’s copilot targets a surprising gap in the LLM market. Over the past year, tools like Cursor and Windsurf have reshaped software engineering workflows. But Kodialam says that even in quantitative fields where machine learning is standard, data specialists lack the kinds of AI copilots available to others.
“It’s super frustrating to see that all the software engineers have Claude Code, all the front-office guys have ChatGPT,” he says, “and the data people have nothing, because no one has built AI that interfaces with data.”
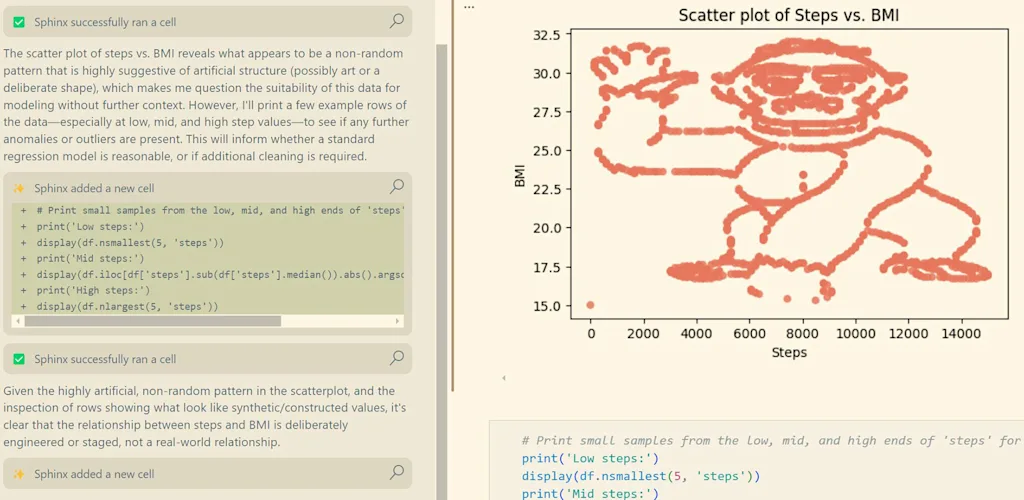
To appreciate the depth of AI’s shortcomings, consider a problem Kodialam calls “the gorilla in the data.” As part of a 2020 study, New York University professors gave data to students and claimed it showed a population’s steps walked versus body mass index. In reality, when the data was plotted on a graph, it resembled a picture of a gorilla.
Only some students noticed the joke; others reported a negative correlation. “The professor told them, ‘You obviously should have looked at the data and seen that it was a monkey and concluded that this was useless data,’” Kodialam says.
When researchers recently gave the same problem to LLMs like GPT-4o, many models were similarly duped. Addressing the gorilla in the data means building “the bridge between the modality of text and images, which is what LLMs live in, and then the modality of numerical tabular data, which is where data lives.”
Sphinx’s AI copilot integrates with Jupyter Notebook, the open-source environment widely used for exploring datasets. It can clean and analyze data, build visualizations and models, and, in a “fully agentic loop,” break tasks into steps executed cell by cell while generating and reading charts to guide its progress. In July, the framework outperformed both general-purpose frontier models and domain-specific tools like Google’s Gemini Data Science Agent on DABstep, a benchmark for multistep data reasoning.
“With Sphinx, you just say, ‘Okay, segment the customers in a reasonable way.’ It does it,” Kodialam says. “You say, ‘Actually, I don’t like that clustering. Can you make it better in this way or that way?’”
That speed and ease of use has already shown results in practice. Brian Tate, CEO of drinkable oatmeal brand Oats Overnight, said in a statement that Sphinx has helped his company’s data scientists “uncover patterns in shopper behavior in minutes instead of hours or days.”
Sphinx isn’t the only firm trying to use foundation models and tools like vector databases to help customers wrangle sprawling and disparate datasets. And demand is rising, as executives try—for real this time—to make foundation models actually worthwhile. Business intelligence vendors like Tableau and Palantir offer AI tools and elaborate dashboards; more technical data vendors, like Snowflake and Databricks, have been adding features to allow nonexperts to analyze data. (Sphinx’s investors also include executives at Databricks, Windsurf, and Together AI.)
The AI lessons Sphinx is building on
Dashboards can be nice to look at, but Kodialam sees more value in “asking the right question at the right time and getting an answer very quickly.”
“You talk to leaders,” he says, “and they’re like, ‘Yeah, I look at like about 2 of the 500 dashboards in my company ever. Most of the time a dashboard is built, I look at it once and then I move on, because the reason the dashboard is built is to answer an acute question.’ That’s obviously not what a dashboard is for, and answering acute questions is what Sphinx is trained at.”
How else does Sphinx differ from a stand-alone system like Palantir’s? Kodialam emphasizes Sphinx’s quick onboarding process, and its “fluid, semantic” approach to dynamic datasets. “You shouldn’t need to have a complicated, human-driven, brittle process to organize your data,” he says. “The AI should organize your data on its own.”
Kodialam says he’s bringing a few other big lessons with him from Wall Street.
One: Complex AI-based processes are both powerful and fragile. “Small changes to the system as a whole can lead to massive performance increases,” he says. But this is a double-edged sword. “If you get it right, you can do great things. But also constant vigilance is needed, and every single part of the stack can break the entire process.”
The second lesson is that data itself is the real advantage. Companies with vast reserves will always have the upper hand, while newcomers face an uphill climb. As Kodialam puts it, “Incumbents with a lot of data are going to do a really great job at deploying AI, and people who are just kind of emerging as startups without a lot of data are probably going to have a hard time.”
Relatedly, Kodialam stresses the importance of privacy. Data, he says, is often viewed as a company’s most valuable asset, and firms will only trust an AI partner if their information is handled like a protected resource rather than something stored or reused after passing through an API.
One basic challenge—and opportunity—is that many companies with plenty of data don’t examine it closely. Kodialam says data scientists should “spend their time thinking about, What is a hypothesis that I need to think about for my business? What is the point of this hypothesis? How does it make dollars? How does it improve the bottom line? How do I interpret it?”
He adds: “They can focus on that layer, where their intelligence and creativity and understanding of their business actually adds value, and get things done incredibly quickly once they have those ideas.”
One big challenge for Sphinx now is incorporating the data that’s not yet data: the tribal knowledge in an institution, the know-how of “some person who’s been there for 10 years and just happens to know the secret way to interpret the data that will make it sing.”
But that data is often in people’s heads, not written down. “Like a junior hire,” Sphinx’s copilot can be trained to incorporate this process knowledge into its agentic framework too. “There is not really a lot of data on data science,” Kodialam says, which is “kind of ironic, given that it’s data about data.”
Kodialam honed his pragmatic approach to AI while working with healthcare data as a student at the Massachusetts Institute of Technology and, later, as a quantitative researcher at Citadel, Wall Street’s most profitable hedge fund, using torrents of structured and unstructured data to beat the market. He ended up running a research team focused on AI, where there was little room for error or hallucination. “With a lot of AI applications right now, you can just generate something cool and that’s good enough. But in finance, you will not make money if you’re wrong,” he says.
Like the models, the humans who keep those models up-to-date must be high-performing and willing to work long hours. No wonder, then, that big AI companies have been luring Wall Street quants with gigantic pay packages, part of an industry-wide talent blitz. Kodialam says he’s lost candidates to AI giant Anthropic, but he gets it. “The only real moat you have in AI is talented people,” he says.
Still, while many AI researchers may be focused on AGI, Sphinx hopes to attract candidates “who want to do something useful now.” Many of them come from industries like finance, “where the reward function is a lot more short term,” Kodialam says. “You do the right thing and the alpha makes money tomorrow.”
As for the impact of Sphinx’s AI tools on quants and other data professionals, Kodialam is optimistic.
“We see this as a way to make people more productive, not to replace anyone,” he says. “There is so much value to be had in most companies’ data if they’re able to optimize what they’re doing—everything from supply chain to pricing to marketing—that the existing cohort of data scientists could easily grow by 10x and still be delivering massive value.”
Kodialam’s obsession with the here and now comes with a longer-term vision about the future of AI. If foundation models can’t grok data in all of its forms—if they can’t do the work of data science—they won’t reach the next level of intelligence.
“The place where humans are really good compared to AI right now is that humans are very multimodal,” he says. “Naturally, if I give you a new modality, you can usually mess around with it and figure it out: audio, music, structured data, unstructured data, touch, smell. There are so many modalities that humans can just generalize over very quickly. AI is kind of stuck in whatever modality the person who trained it was able to tokenize.”
In the near term, Kodialam predicts that those kinds of shortcomings will make it easier to separate vaporware from the good stuff.
“A good AI system is very useful; a bad AI system is complete trash,” he says. “And there’s no difference in a lot of people’s minds because it’s just AI. But the quality matters so much. And I think that’ll just become increasingly obvious as AI gets deployed in every company, and some companies are not winning and others are.”
Related Posts

Nokia CEO says AI investments won’t slow down because it’s a ‘super cycle’ with ‘massive’ prospects
Nokia CEO Justin Hotard said AI is a "super cycle"…
I was laid off by Oracle 2 years ago and still can’t find a job. I’ve blown through my savings and now sell antiques to stay afloat.
Clair Todd Clair Todd Clair Todd has been struggling to…